Giving QR Codes Superpowers
 QR codes are popular because they can store more information than bar codes, but they can’t store binary data and have no inherent structure. In this post, I’ll show how to overcome these limitations and give QR codes superpowers!
QR Codes and Their Limitations QR codes were invented by the Japanese company …
QR codes are popular because they can store more information than bar codes, but they can’t store binary data and have no inherent structure. In this post, I’ll show how to overcome these limitations and give QR codes superpowers!
QR Codes and Their Limitations QR codes were invented by the Japanese company … NixOS has a lot of really cool ideas, but unfortunately installing on a VM is still tricky. This guide is designed as a “just get me something working, please!” way to get a headless NixOS install up and running in a libvirt VM.
Prerequisites You will need to have libvirt and virt-install on your system.
On …
NixOS has a lot of really cool ideas, but unfortunately installing on a VM is still tricky. This guide is designed as a “just get me something working, please!” way to get a headless NixOS install up and running in a libvirt VM.
Prerequisites You will need to have libvirt and virt-install on your system.
On …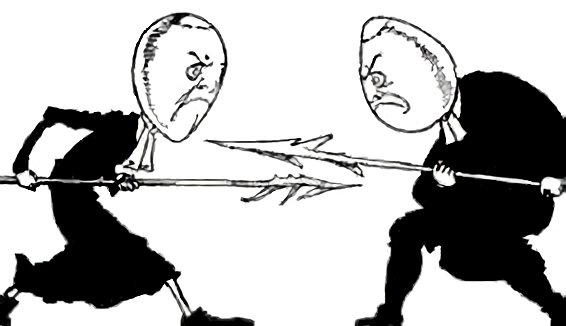 Byte Endianness in computers has been a constant source of conflict for decades. But is there really a clear advantage to one over the other? Let’s explore together!
Origins The terms “Little Endian” and “Big Endian” originate from Jonathan Swift’s 1726 novel “Gulliver’s …
Byte Endianness in computers has been a constant source of conflict for decades. But is there really a clear advantage to one over the other? Let’s explore together!
Origins The terms “Little Endian” and “Big Endian” originate from Jonathan Swift’s 1726 novel “Gulliver’s …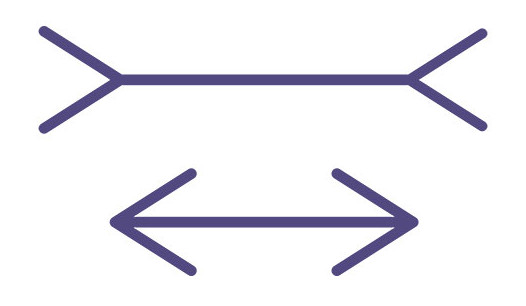 Line lengths, like tab sizes, tabs vs spaces, and brace positioning, are among the most contentious topics in programming. This is to be expected, as predicted by Sayre’s Law : “In any dispute, the intensity of feeling is inversely proportional to the value of the issues at stake.” Naturally, …
Line lengths, like tab sizes, tabs vs spaces, and brace positioning, are among the most contentious topics in programming. This is to be expected, as predicted by Sayre’s Law : “In any dispute, the intensity of feeling is inversely proportional to the value of the issues at stake.” Naturally, …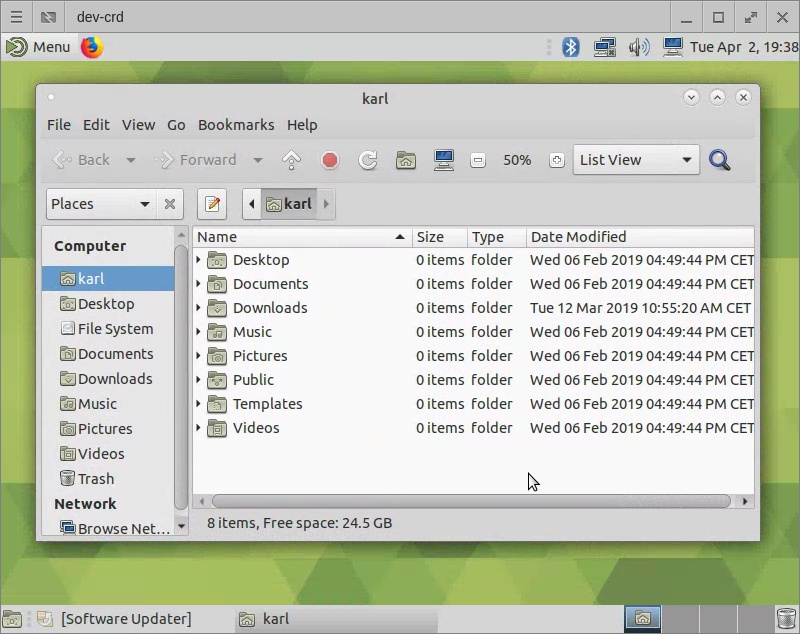 Have you ever wanted a persistent Linux virtual desktop that you could host anywhere and access remotely? Now you can do it, using only Ubuntu and a cheap VPS!
I like having deterministic work environments. Disaster recovery becomes a cinch when you can just destroy and rebuild your desktop container, map your home …
Have you ever wanted a persistent Linux virtual desktop that you could host anywhere and access remotely? Now you can do it, using only Ubuntu and a cheap VPS!
I like having deterministic work environments. Disaster recovery becomes a cinch when you can just destroy and rebuild your desktop container, map your home …