How important is uptime to you? How bad would it be if your services went down for 10 seconds? 10 minutes? 10 hours? 10 days? Every system has its breaking point, where the consequences become so severe that heads start rolling.
Once the breaking point for downtime is shorter than your worst-case time for fixing things, you need high-availability.
What is High Availability?
High availability is a mechanism whereby multiple redundant services collaborate to minimize interruptions. When one service goes down, another, identical service picks up the slack.
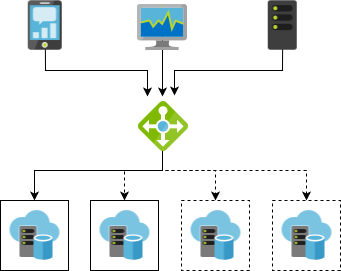
We see redundant systems wherever failures are too costly. Commercial airplanes have many redundant systems and sensors, as does the space shuttle and ISS. RAID arrays offer protection against data loss due to disk failures. High availability simply brings redundancy to a new level. Redundancy decreases risk, but invokes a setup and maintenance cost. Much like with insurance, the kind and amount of redundancy you need depends on your risk profile.
I’ll talk briefly about two kinds of redundancy: network level and service level. In order to minimize costs and avoid data corruption, it’s important to know their differences:
Network Level High Availability
High availability at the network level involves switching a virtual IP address between different nodes that run the same service. When a node goes offline, the virtual IP is claimed by another node running the same service. This functionality can also be used to provide load balancing, where the virtual IP address floats between servers during normal operation.
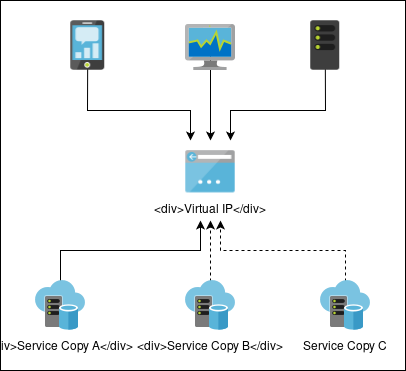
This kind of setup has the advantage of being simple, but it doesn’t handle the failing services themselves. The downed service remains down, and must be restarted manually. If all redundant services eventually fail without someone intervening to restart them, the service goes offline completely. As well, this kind of setup has no way to detect misbehaving nodes. If a node is accepting network connections, it must be OK, even if the service inside the node is behaving badly. It’s up to the nodes themselves to monitor their own health.
Since the management layer has no knowledge of what’s inside the nodes, all redundant services must run simultaneously, which can cause problems if they need to write to shared resources such as network filesystems. Corruption is likely, unless the services or the shared resources are carefully designed to avoid it.
Service Level High Availability
High availability at the service level (clustering) is more complicated. The management layer must have knowledge about how to start, stop, and monitor services on the various nodes they’re running on. This requires a special management communication channel to the nodes (a heartbeat network ).
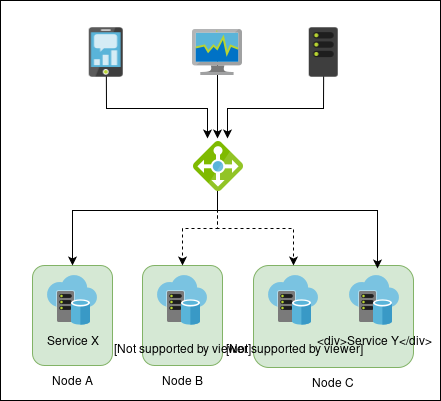
The service interfaces can be via virtual IP or some other mechanism. Nodes can run any number of services. Management can run separately, or via a quorum protocol on the nodes themselves.
A very important distinction between the HA levels is that network level HA ensures that at least one copy of a service is running, while service level HA ensures that at most one copy of a service is running. Since only one copy of a service can run at a time, it can write to shared resources without fear of corruption. And since service level HA can directly manage services, it can fence off a misbehaving node (cut it off from all resources so that it can’t do any damage), and then kill or restart it as needed.
The services themselves can be anything: web servers, file systems, databases, directory services, even virtual IPs. Anything that provides access to a resource, and has a service management interface , can be managed by the cluster.
Since management is at the service rather than node level, there’s no need to have homogenous nodes. You can have different or even multiple services on different nodes, depending on your needs and cost sensitivity, and there are numerous node configuration possibilities to choose from.
In Closing
High availability isn’t for everyone. The turning point comes when the worry of potential downtime starts keeping you up at night. Once that happens, it’s time to look into high availability infrastructure. In future posts, I’ll write some concrete examples of network level and service level high availability you can run on Ubuntu Linux.