Line lengths, like tab sizes, tabs vs spaces, and brace positioning, are among the most contentious topics in programming. This is to be expected, as predicted by Sayre’s Law : “In any dispute, the intensity of feeling is inversely proportional to the value of the issues at stake.” Naturally, contentious topics make for popular blog posts, so here we go!
I’ve been programming for almost 40 years, 25 of those professionally. I’ve lived through many of the later seismic shifts in programming discipline, have written much code on actual 80x25 CRT terminals, and have participated in many, many contentious-yet-trivial discussions in programming.
Since our contentious trivial topic is line width, I’d be interested to see how my recent projects have held up to the ideal line width. What’s the ideal, you ask? That’s a secret!
Let’s have a look at my projects directory, containing around 150 semi-recent projects from the last 10 years, mostly in C, C++, Go, Java, Python, Objective-C, and Bash.
We’ll start in the command line. Here’s a quick shell command to print a frequency graph of line lengths for all go files:
1find . -type f \( -name "*.go" \) -exec awk '{print length}' {} \; | \
2 sort -n | \
3 uniq -c | \
4 awk '($2 >= 75) && ($1 >= 20) {printf("%3s: %s\n",$2,$1)}' | \
5 awk 'NR==1{scale=$2/30} \
6 {printf("%-15s ",$0); \
7 for (i = 0; i<($2/scale) ; i++) {printf("=")}; \
8 printf("\n")}'
I artificially cut off line lengths under 75 (I’m only interested in longer line lengths), and anything with less than 20 occurrences. This keeps the graph small while still providing eyeball-level usefulness. The scaling is clunky (divide by 30), but it’s good enough for here.
Legend: Line-width: count graph
1 75: 327 ==============================
2 76: 202 ===================
3 77: 486 =============================================
4 78: 360 ==================================
5 79: 386 ====================================
6 80: 221 =====================
7 81: 134 =============
8 82: 137 =============
9 83: 102 ==========
10 84: 119 ===========
11 85: 121 ============
12 86: 131 =============
13 87: 98 =========
14 88: 85 ========
15 89: 53 =====
16 90: 55 ======
17 91: 77 ========
18 92: 117 ===========
19 93: 72 =======
20 94: 72 =======
21 95: 52 =====
22 96: 55 ======
23 97: 59 ======
24 98: 61 ======
25 99: 70 =======
26100: 48 =====
27101: 46 =====
28102: 45 =====
29103: 27 ===
30104: 35 ====
31105: 24 ===
32106: 39 ====
33107: 24 ===
34109: 26 ===
35110: 21 ==
36111: 23 ===
Neato! That was fun, but it’s better to use the right tool for the job. Enter Gnuplot !
Gnuplot is a graph generator that can be invoked from the command line to generate pretty plots and graphs. It’s incredibly useful and powerful, but as a result has a steep learning curve. Here’s a quick gnuplot program copied from my neighbor .
linecounts.gnu:
1reset
2
3intervals=40
4min=70
5max=150
6width=(max-min)/intervals
7
8hist(x,width)=width*floor(x/width)+width/2.0
9
10set term png
11set output "plot.png"
12set xrange [min:max]
13set yrange [0:]
14set style fill solid 1.0
15set xlabel "Line Width"
16set ylabel "Frequency"
17
18plot "/dev/stdin" u (hist($1,width)):(1.0) smooth freq w boxes lc rgb"#2a9d8f" notitle
I’m setting the min to 70 since I’m only interested in the longer lines, and capping at 150 because I probably have code-generated code in there somewhere, and some code generators create lines thousands of characters long.
I’ve found in my experience that line lengths greater than 120 or so are harder to scan. Probably this has something to do with how our eyes focus. That said, the odd long line doesn’t really bother me if it’s done to preserve the structure in an eye-scan friendly way.
To invoke, we generate line count data the same as before, but send it to gnuplot instead:
1find . -type f \( -name "*.go" \) -exec awk '{print length}' {} \; | gnuplot linecounts.gnu
This will output a file plot.png, containing the line counts of all files in all subdirs ending with .go. Change the \( -name "*.go" \) section to capture the file types you’re interested in.
Tooling finished! Now let’s have a look at my line widths for various languages!
My Projects
C: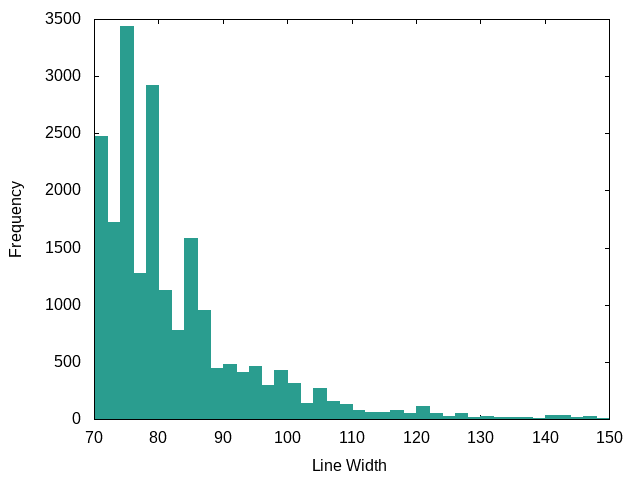
C++: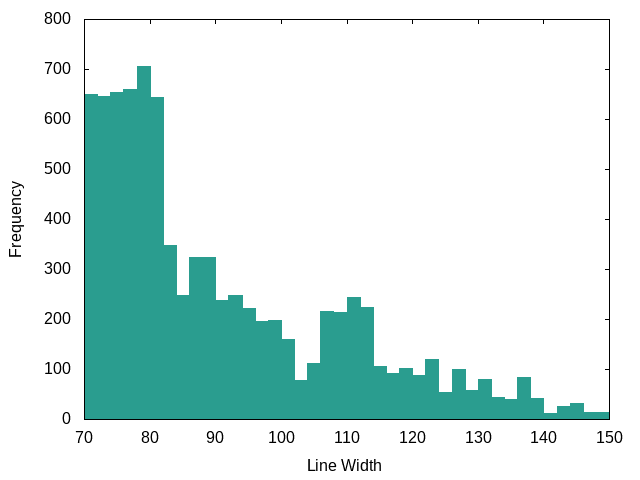
C++ really pushes the line lengths, but that’s to be expected given how verbose templates are.
Go: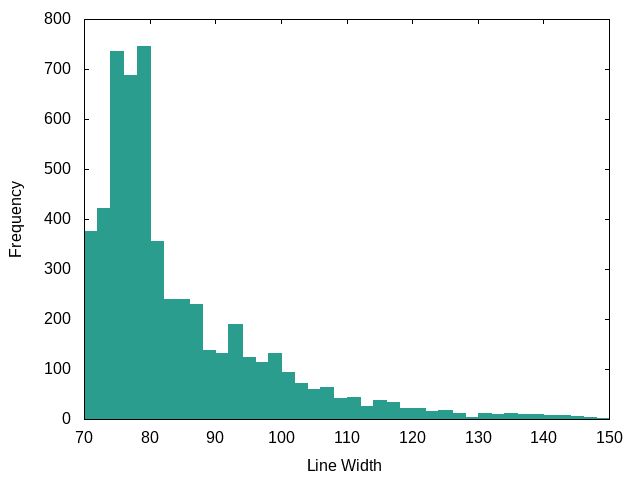
Java: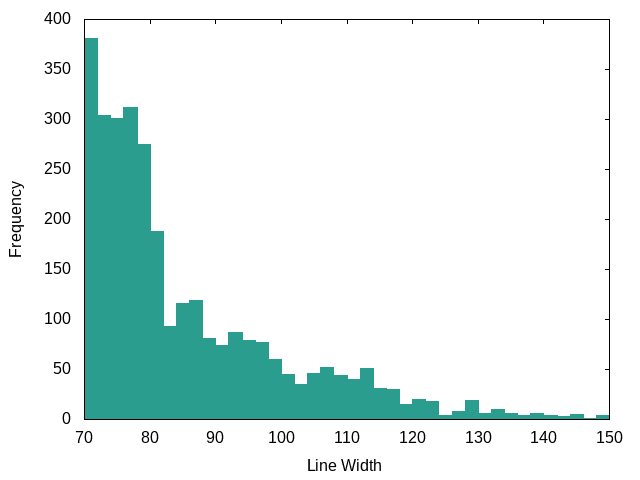
Java is slightly higher than C and Go, but overall relatively stable.
Objective-C: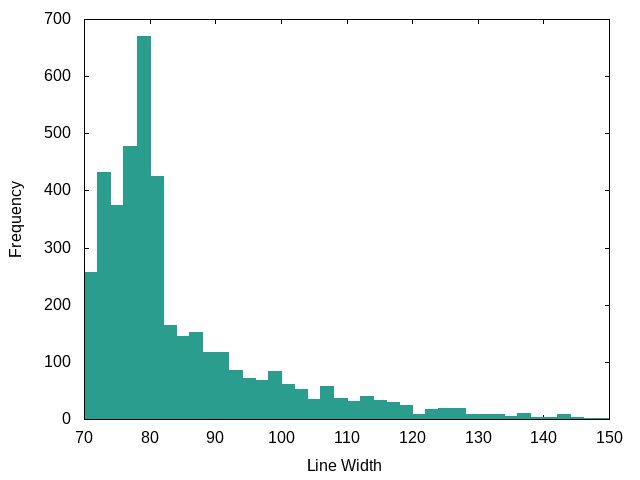
Python: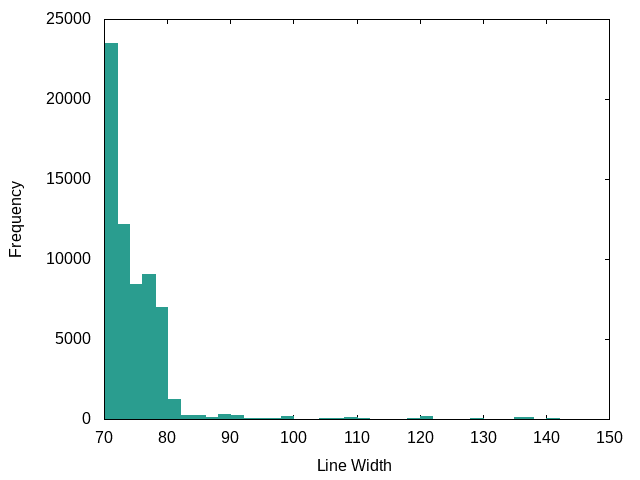
Honestly, I’d expected Python line lengths to be longer, but I guess I really made an effort to adhere to PEP-8.
Bash: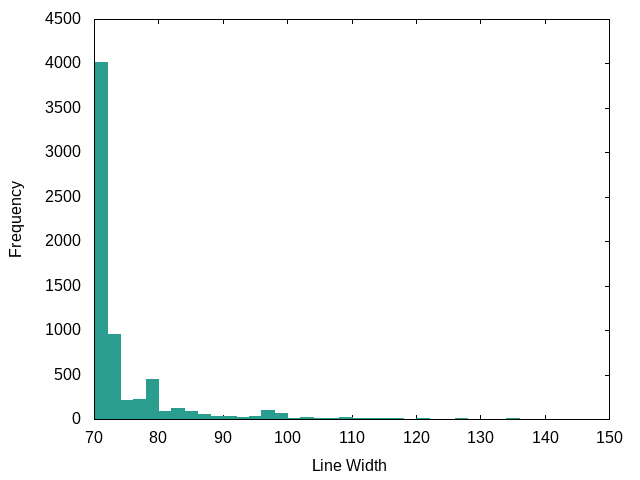
Bigger Projects
Let’s have a look at some of the more popular projects out there:
C (Linux Kernel):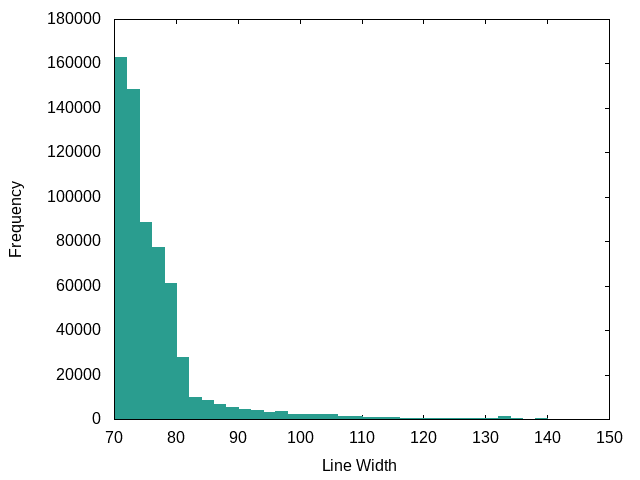
Fairly strict adherence to 80 cols.
C++ (Apple’s Swift language):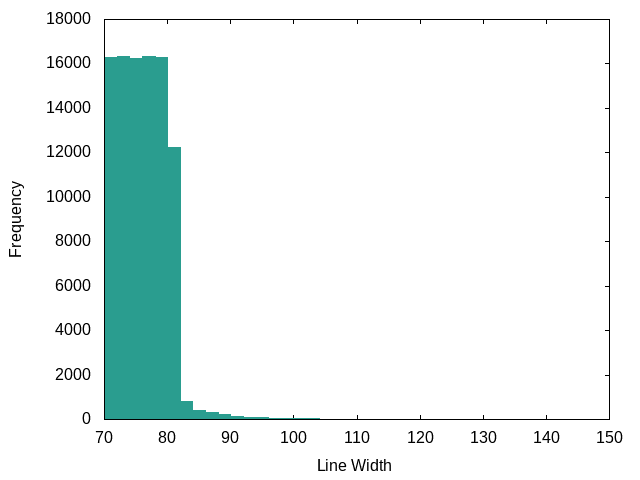
VERY strictly 80 cols.
Go (Go compiler and standard library):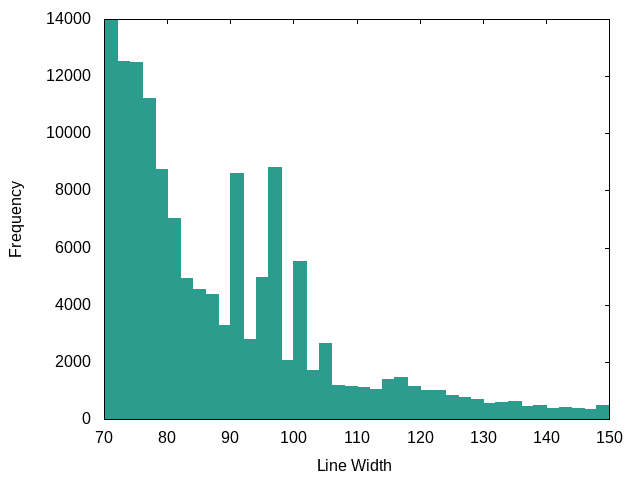
The Go compiler and library have some generated code in it, but also it looks like they don’t worry so much about line lengths.
Java (Spring-Boot):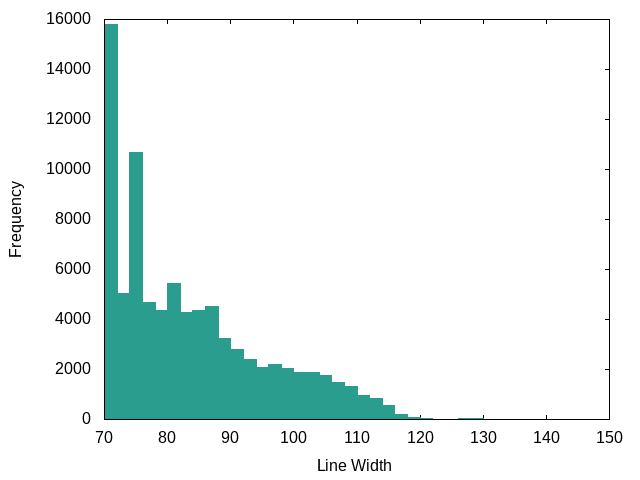
Spring-boot looks like it has a style around 100 or so.
Javascript (React):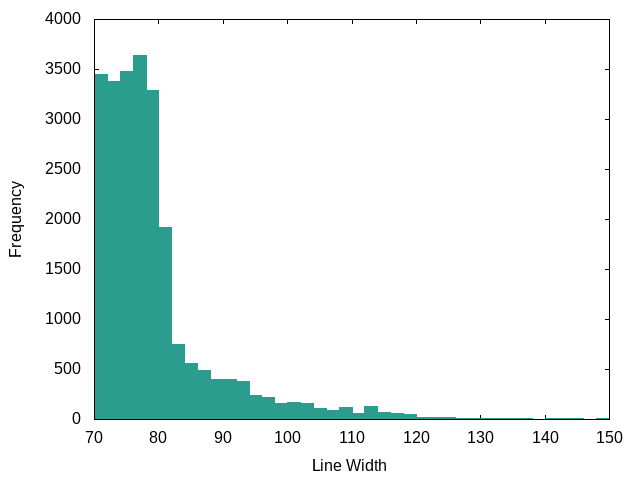
React looks like it has an ideal of 80 cols.
PHP (Symfony):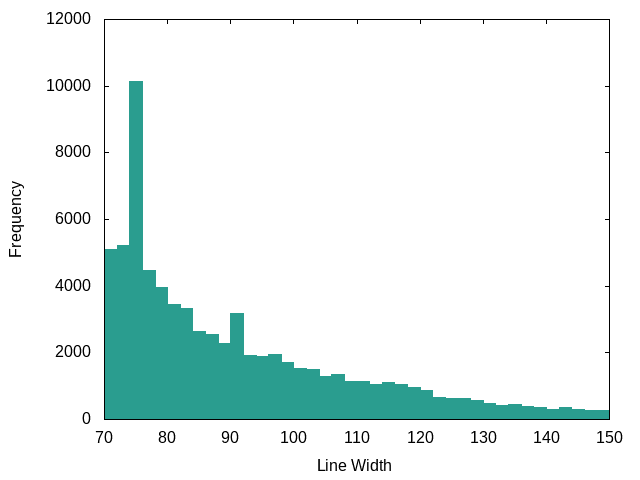
PHP stuff in general doesn’t place much importance on line length.
Python (Django):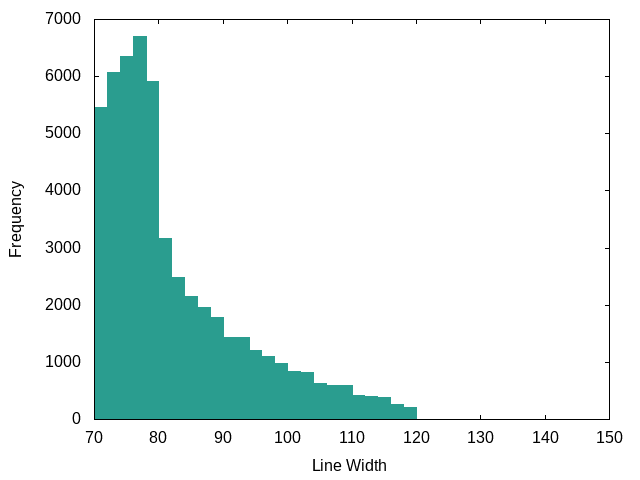
Not very PEP-8, is it ;-)
Line lengths are a contentious issue in programming, so we tend to write many rules and standards about it, even if we don’t actually follow them. But I wonder if we might be better served by a desire path approach? If we observe what people are actually doing, we can probably come up with more natural feeling line length conventions.